[TOC] #### 1. 慢查询介绍 ---- 常见面试题:如何从一个大项目中,迅速定位执行速度慢的 SQL 语句 ?此时可以使用慢查询定位执行较慢 SQL 语句 慢查询就是在日志中记录运行比较慢的 SQL 语句,是指所有执行超过 long_query_time 参数设定的时间阈值的 SQL 语句查询 #### 2. 慢查询状态 --- ```bash # 查看是否开启慢查询日志 ON 1 开启 OFF 0 关闭(默认是关闭的) show variables like 'slow_query_log'; # 开启和关闭慢查询日志(临时有效,重启 MySQL 服务后恢复原来的值) set global slow_query_log = 1; set global slow_query_log = 0; ``` 想要永久生效必须修改配置文件 `my.conf`,将以下配置项放入配置文件,重启 MySQL 服务生效 ```plaintext slow_query_log = 1 ```  #### 3. 慢查询时间阈值 --- 上面在介绍慢查询时,已经说明慢查询日志中记录的是超出时间阈值的 SQL 语句 这个时间阈值可以通过下面这个命令查看,默认是 10 秒 ```bash # 查看当前慢查询时间阈值 show variables like 'long_query_time'; # 临时修改慢查询时间阈值 (1 秒) set long_query_time = 1; ```  在配置文件 my.conf 中添加配置项,使设置的时间阈值永久生效 ``` long_query_time = 2 ``` 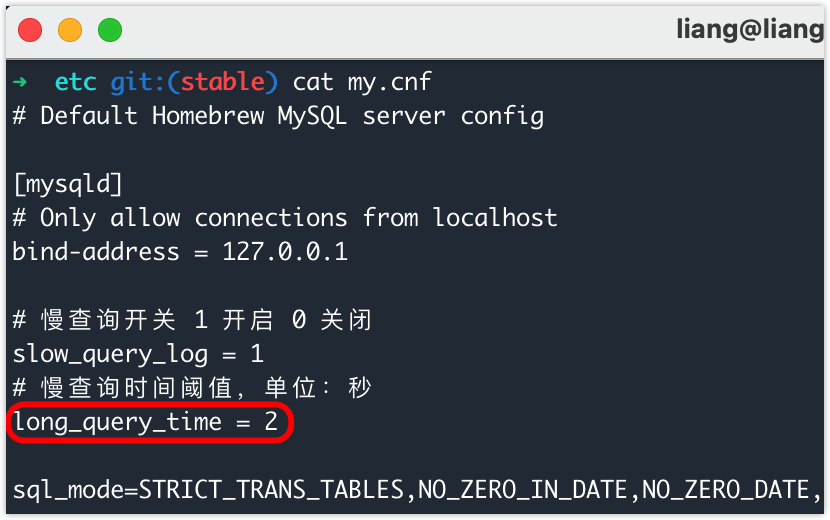 #### 4. 构建大表,测试慢查询 --- 创建一个数据库,执行下面 SQL ```sql CREATE TABLE dept( /*部门表*/ deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/ dname VARCHAR(20) NOT NULL DEFAULT "", /*名称*/ loc VARCHAR(13) NOT NULL DEFAULT "" /*地点*/ ) ENGINE=MyISAM DEFAULT CHARSET=utf8 ; CREATE TABLE emp( empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/ ename VARCHAR(20) NOT NULL DEFAULT "", /*名字*/ job VARCHAR(9) NOT NULL DEFAULT "",/*工作*/ mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*上级编号*/ hiredate DATE NOT NULL,/*入职时间*/ sal DECIMAL(7,2) NOT NULL,/*薪水*/ comm DECIMAL(7,2) NOT NULL,/*红利*/ deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*部门编号*/ )ENGINE=MyISAM DEFAULT CHARSET=utf8 ; CREATE TABLE salgrade ( grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, losal DECIMAL(17,2) NOT NULL, hisal DECIMAL(17,2) NOT NULL )ENGINE=MyISAM DEFAULT CHARSET=utf8; -- 测试数据 INSERT INTO salgrade VALUES (1,700,1200); INSERT INTO salgrade VALUES (2,1201,1400); INSERT INTO salgrade VALUES (3,1401,2000); INSERT INTO salgrade VALUES (4,2001,3000); INSERT INTO salgrade VALUES (5,3001,9999); # 创建存储过程 delimiter $$ create function rand_string(n INT) returns varchar(255) #该函数会返回一个字符串 begin #chars_str定义一个变量 chars_str,类型是 varchar(100),默认值’abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ’; declare chars_str varchar(100) default 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; declare return_str varchar(255) default ''; declare i int default 0; while i < n do set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1)); set i = i + 1; end while; return return_str; end $$ create procedure insert_emp2(in start int(10),in max_num int(10)) begin declare i int default 0; #set autocommit =0 把autocommit设置成0 set autocommit = 0; repeat set i = i + 1; insert into emp values ((start+i) ,rand_string(6),'SALESMAN',0001,curdate(),2000,400,floor(rand()*5+5)); until i = max_num end repeat; commit; end $$ delimiter ; # 调用刚刚写好的函数, 1800000条记录,从100001号开始 call insert_emp2(100001,4000000); ``` 查询 emp 表数据,执行 1.55 秒 ``` mysql> select * from emp; +--------+--------+----------+-----+------------+---------+--------+--------+ | empno | ename | job | mgr | hiredate | sal | comm | deptno | +--------+--------+----------+-----+------------+---------+--------+--------+ | 100002 | BzVfMu | SALESMAN | 1 | 2022-05-15 | 2000.00 | 400.00 | 8 | | 100003 | wcUtjQ | SALESMAN | 1 | 2022-05-15 | 2000.00 | 400.00 | 7 | | ... | ... | ... | ... | ... | ... | ... | ... | +--------+--------+----------+-----+------------+---------+--------+--------+ 4000000 rows in set (1.55 sec) ``` ```bash # 查看慢查询日志文件存放位置 show variables like 'slow_query_log_file'; ``` 设置 long_query_time = 1,此时会生成慢查询日志,文件内容如下所示 ```plaintext # Time: 2022-05-15T02:31:37.897427Z # User@Host: root[root] @ localhost [] Id: 2 # Query_time: 1.548641 Lock_time: 0.000156 Rows_sent: 4000000 Rows_examined: 4000000 SET timestamp=1652581897; select * from emp; ``` #### 5. 慢查询优化 ---- 面试高频考点:现在有个 SQL 查询比较慢,应该从哪几个方面优化 ? 优化慢查询需要遵循一套标准的排查和优化流程,从定位到分析再到优化: + 定位慢查询语句:开启慢查询日志,并且设置阈值时间 + 分析执行计划:使用 `explain` 关键词,查看它的执行计划 + 核心优化手段:索引优化、SQL 语句改写 索引优化(最常见): + 避免索引失效(这是80%慢查询的根源): + 避免在 where 条件中对索引列使用函数,并且应遵守最左侧原则,注意范围查询打断 + 模糊查询:尽量不使用后缀模糊查询,因为 `%abc` 会导致索引失效 + 类型隐式转换:确保查询条件的数据类型与字段类型一致,如 id 时 int 类型,就不要用 `where id = "123"` + 创建高效索引: + 联合索引:创建合适的联合索引可以同时满足过滤和排序,避免 `Using filesort` + 覆盖索引:尽量只查询需要的字段,并让这些字段都包含在索引中。这样可以直接从索引中获取数据,无需回表 SQL 语句改写: + 避免 `select *`:只查询必要的列,这不仅能减少网络传输,还能增加使用覆盖索引的机会 + 深度优化分页:`limit 100000, 10` 这种查询非常慢,因为 MySQL 需要扫描并丢弃前 10 万条数据 + 优化方案:使用 “游标分页” 或 “延迟关联”。 + 例如,记录上一页最大的 ID,下一页查询使用 `where id > last_max_id limit 10` 表结构与设计: + 主键选择:优先使用自增 ID 作为主键,避免使用无序的UUID,以减少B+树索引的分裂和碎片 + JOIN 优化:遵循 “小表驱动大表” 的原则,并确保 `join` 关联的字段上有索引